- DataArts News
Researchers Turn to Machine Learning to Evaluate Equitable Practices in Grantmaking
- Posted Dec 08, 2022
Technological buzzwords abound, and new technologies are created and shared widely every day. The hype around these new ideas spurs innovation in the arts and culture field with mixed results in the short- and long-term. With examples like NFTs, augmented/virtual reality in Pokémon Go, and the use of machine learning for donor identification, our sector strives to harness these technologies, but difficulties in infrastructure, sustainability, and bias in these systems can make it difficult to provide transparency and equity to the audiences we aim to serve. Technologies such as Smartify’s computer vision exhibition application and Salesforce's AI for Good donor identification software show positive uses of these technologies, but the success of individual implementation cases vary.
Through all of this innovation, however, few computational tools and methods have been created to assist grantmakers in their efforts to cultivate equitable funding practices to support the sector. Knowing the hurdles present in technology integration within our field, is it even possible to create something useful to support funders? Can we mitigate the bias found in these systems to make them trustworthy? Well, we think we can.
SMU DataArts’ new three-year strategy[i] and external developments in the field[ii] prompted us to explore how machine learning could be used to evaluate grantmaking. The results of our research indicate we are on the right track in developing this technology.

How Does It Work?
In a forthcoming publication in the Institute of Electrical and Electronics Engineers (IEEE) 2022 proceedings on Big Data, we explore the application of machine learning models to evaluate the feasibility of developing an accurate, transparent, and explainable process for assessing grantmaker decision-making. Let’s dig in.
Our modeling process starts with data from an arts and culture grant program dispersed by a grantmaker in a large city in the U.S. Midwest. Capturing application data regarding finances, organization age, discipline, and application results allowed us to limit the scope of this exploratory research while still capturing the profile of each applicant organization. We then focused on a machine learning model known as a decision tree, which splits the data successively on various variables to minimize impurity and ultimately classify each application by the splits to get to the final award decision. This information can be visualized in a tree diagram to help guide people through the “decisions” made by the algorithm. This makes it a very transparent and explainable machine-learning model.
Here’s a simple example. If a dataset had a variable “Grant Amount” where non-funded organizations had a value of $0 and funded organizations had grant amounts of at least $1, that variable, or node, could split based on the value. The figure below shows this simple example, reading the “decisions” from the top down:
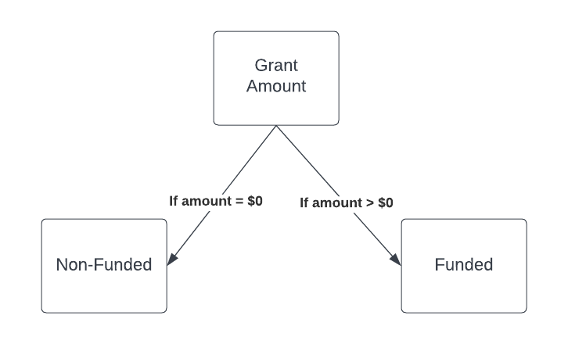
Simple Decision Tree Example
This process becomes more complex as we include more variables, but the underlying logic remains the same. Our exploration of the grant application data with a decision tree model resulted in the following partial tree diagram:
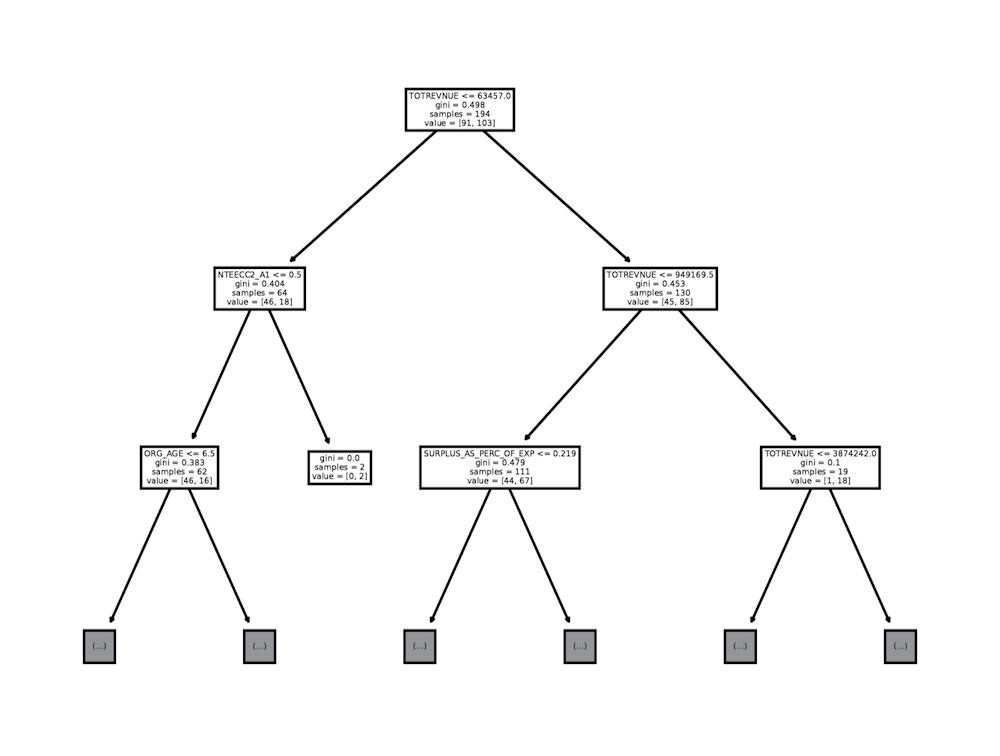
Partial Decision Tree Results
The primary nodes, or the rectangular boxes where the data is “split,” help us identify the primary factors that lead us from raw data to the application decision in the most efficient manner (fewest steps). In this example, total revenue proved to be one of the most decisive variables in ultimately determining application success. However, the nuance of the full decision tree includes over 80 nodes, all contributing to making the final decisions.
The expansiveness of this decision tree requires that we closely evaluate the accuracy of the model to minimize over- and under-fitting of the data while also maintaining high levels of accuracy. It should be noted that this model is not sentient and perhaps would not capture the nuance of the application review process that funders go through with applicants. It simply identifies the most efficient path from start to finish based on the application data itself. Even with that caveat, this information can still be very powerful for grantmakers.
How Would a Grantmaker Use This Information to Improve Equity Outcomes in Funding?
The nodes of the decision tree are key. As we explore each branch within the tree from top to bottom, the variables selected at each node indicate the potential key factors leading to funding. If total revenue proved to be a key factor down an entire branch, that may indicate that for some organizations, simply having a budget in the “correct” range could lead to positive funding outcomes regardless of other application components. Conversely, if a path through the tree focused primarily on discipline and organization age, that could tell a grantmaker how their decision-making might be skewed towards certain types of organizations.
This information can provide a check against a funder’s stated goals and application requirements relative to which pieces of application information actually lead most efficiently to funding. A grantmaker could then choose to evaluate and adjust its funding criteria to better align with its stated goals if there is any conflict. They could also choose to reduce some application requirements that are less predictive of funding success, removing some barriers to entry for organizations.
Beyond evaluation of current and past grantees, this type of machine learning modeling provides a mechanism by which grantmakers can potentially identify organizations in their communities that perhaps fit their funding portfolio but have never applied for a grant in the past. For this project, we were able to use publicly available data and identify 345 organizations that had never applied to the funder but whose organizational characteristics matched those that had been funded in the past. You can see a map of the funded organizations (blue dots) and the high-potential non-applicant organizations (red dots) on the map below.
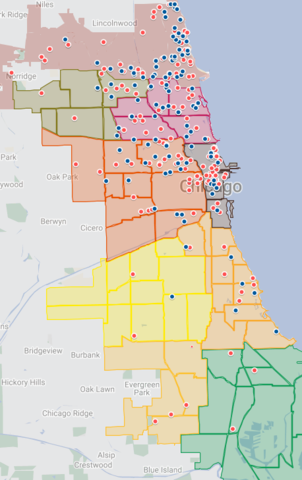
Using this information, we can better tailor our focus and outreach to support our communities and lift up organizations that have the potential to be successful in a grantmakers portfolio.
What's Next?
When developed well, machine learning can be a powerful tool, and we are just in the early stages of developing this work to support the field. This technology can be used to:
- Improve application evaluation efficiency;
- Provide an evaluation mechanism for funders relative to their stated goals;
- Assist funders in identifying new applicants; and even
- Provide a tool for grant applicants to assess the comparative “quality” of their applications.
However, before deploying any technology in this realm, considerations around bias in the data and systems have to be acknowledged, mitigated, and even abandoned if the results point to harmful outcomes. For example, if past funding practices systematically excluded a segment of the population, no machine learning model will correct this issue in formulating predictions. Nevertheless, the model could be very useful in evaluating and identifying the exclusion of those segments and suggest a course correction for the funder. That same model would be a poor predictor in identifying new organizations in a community since the underlying data would create a model built on the patterns found in the exclusionary grantmaking of past years.
Moving forward, we are going to refine our research and dig even deeper. We are currently cultivating grantmaker interest and have plans to evaluate grant programs of both arts organizations and artists, exploring how application requirements and review processes impacted funding decisions. Through this collaboration, we will expand the model to include full application materials including narratives, finances, and perhaps work samples as well as evaluate panel reviewer characteristics relative to their grant decisions.
By approaching this modeling and evaluation through multiple aspects and phases of the grant application process, we hope to harness the benefits and power of machine learning to assist our sector and grantmakers in contributing to more equitable funding models.
[i] In October 2022, SMU DataArts released a new three-year strategy where we noted our aim to “[deepen] our research and data integration capabilities, … share high-quality insights with the field, and [prioritize] ways we can contribute to more equitable funding models.” To advance our goal around equitable funding models, we specifically plan to conduct “research projects that celebrate the arts and culture of communities of color, and advance equity in access to art, cultural funding and the sector at large.”
[ii] Our strategy coincides with other equity efforts in the field of arts and culture funding, clearly demonstrated by a bill introduced in Congress to “[support] arts and humanities projects that directly combat systemic racism through the arts and humanities,” which is to be carried out by the National Endowment for the Arts and the National Endowment for the Humanities with grant panels including BIPOC members in the majority.
Greater Pittsburgh Arts Council joins us for a lively discussion on the potential impact of computational tools used to assist grantmakers in cultivating equitable funding practices and assess the broader ethical context of applying machine learning in this domain. This webinar was held on May 30, 2023.